Is error-free parsing possible? Part I
Written by: Igor Protsenko, with Miriam Khanukaev
Accurate parsing enables Q&A quality — but is it possible?
No matter the industry or sector, businesses regularly deal with the question of how to efficiently process large amounts of info-heavy documents. Organization leaders, including CTOs, CDOs, and CPOs, are often looking for solutions to this question — whether they’re tasked with enabling portfolio managers entrusted with scrutinizing financial documents to analyze revenue, supporting lawyers inundated with contracts and court filings, or empowering recruiters sifting through resumes in attempts to find the best match candidates for the company. Since Large Language Models (LLMs) have introduced technology capable of recognizing text patterns, we at Proxet have long wondered how LLMs can help companies analyze documents and translate information into reliable data - a process otherwise called “document understanding.”
Broadly, the ability to understand the structure and extract useful content of data in a document, is called “parsing.” If LLMs could help summarize long blocks of text, extract information from Excel sheets, or perform a range of advanced indexing tasks like identifying keywords or attaching metadata, not only could they help businesses gain efficiencies through their preliminary analysis, but also save costs and streamline personnel responsibilities.
Unfortunately, while businesses have begun to use LLMs for this very purpose, LLM capabilities remain limited: since LLMs are only able to interpret raw text, we can’t feed in documents that have components like tables, LaTeX formulas, multi-columns, or any sort of format that we, as human beings, rather than machines, rely on to make information easier to read and understand.

Do We Have a Problem?
Whether it be company reports, financial data, legal briefs, CVs, research papers, or any other documents with more complex info, data is rarely laid out in a uniform manner. So, users seeking to accurately process large amounts of organized text in PDFs must rely on tools like parsers, such as AzureForm Recognizer and PyPDF. Those looking to use Excel rely on Openpyxl, which helps convert these raw documents into readable text that LLMs can process.
But to what extent can “off-the-shelf” tools interpret more complex text schemas? This is precisely what we’ll be exploring in this post. Going in, we know that parsers interpret documents by inferring the presence of text blocks through certain heuristics. For instance, if a document has consistent gaps between text blocks, a parser might suggest inputting columns. Tables, on the other hand, are more challenging. A parser might recognize consistent horizontal and vertical gaps or detect graphic elements like lines, but if there’s even a slight misalignment in a table-like structure, the data is subject to misinterpretation.
Below, we explore the limitations of parsers, using PyPDF and Azure Form Recognizer on two use cases. We chose these specialized external parsers because they’re widely used amongst broad organizations and technologists for “out of the box” document understanding. Our ultimate goal, starting with this post, is to push the boundaries by which parsing can accurately infer information from larger data sets. In our subsequent post, we’ll explore whether LLMs themselves can give us a solution to the mistakes parsers create in hopes of uncovering to what extent LLMs can recover the informational flow of these documents.
How well do PyPDF and Azure Form Recognizer process layouts that include tables?
For our first case, let’s consider a job summary document. Organized as a simple 3-column layout including each corresponding job description, the document’s structure allows the reader to easily compare the responsibilities of each role. Say you’re an Organization Designer in healthcare looking at the roles below - you may want to use an LLM to determine whether there’s equitable work distribution. Or, as a recruiter, you may want to use a screening software that matches resumes to each role. Before applying any retrieval-augmented generation (for more details, take a look at our prior published blog: Vectors and RAG), we’ll need the LLM to understand the document, so we input it into the parser.
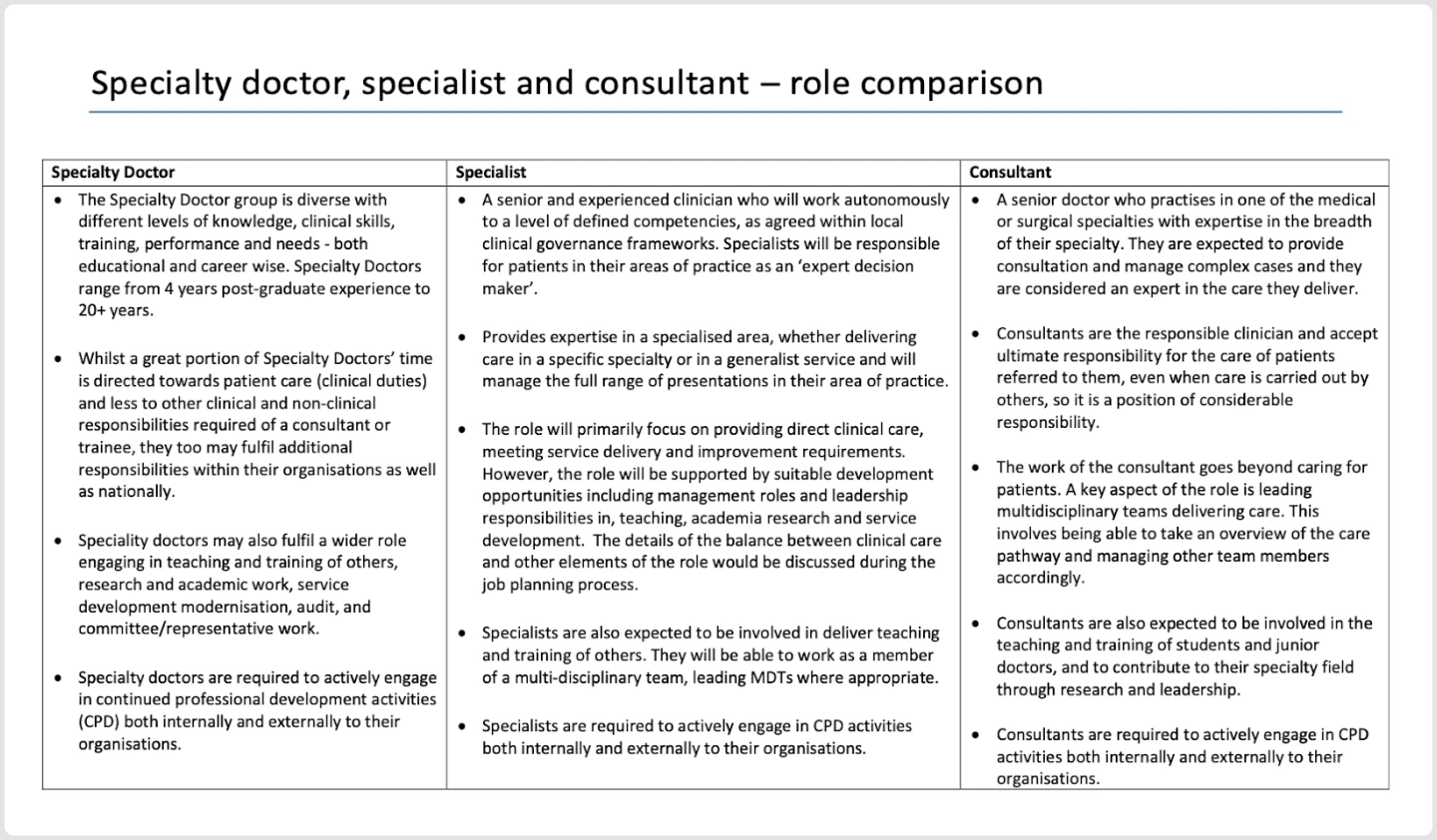
Let’s take a look at what both parsers feed out:

As you can see, the result doesn’t retain any columns, and as a result, all informational flow is lost. We can’t easily infer which job description applies to what role, rendering the result returned by the parser to be essentially useless.
While these two common parsers had trouble interpreting a 3-column layout, we looked to determine if one of the tools would be able to interpret a 2-column layout and retain the rows in the document. We used an excerpt from an academic paper for our testing purposes, but any lawyer or researcher who needs to produce summaries of large research documents and retain insights will encounter them. But once again, our parser (Azure) fails us. If this parsed result were fed into an LLM, the data could be incorrectly interpreted.


What about embedded formulas? Can PyPDF/Azure help process scientific data and formulas?
Scientists and research organizations are yet another group that could potentially rely on LLMs to help synthesize large documents and extract key findings. Unfortunately, however, neither PyPDF nor Azure retain the structure of documents with formulas.
Here’s an excerpt from a scientific paper alongside text returned from the parser:

In the parsed text, words are split in the middle and formed incorrectly. Formulas, figures, and measures that the paper is dissecting (in this case, cluster mass and the density of the Universe) are completely lost. The parsed text is not only inaccurate, but also, essentially unusable.
Specialized parsers, such as MathPix, designed for scientific articles, can help extract useful information from such documents rich with Latex-formulas, figures, and figure descriptions. But for a user to determine whether MathPix is needed, they will have to manually inspect each document and discern whether each document contains a certain scientific notation, non-linear layout which might be difficult to parse. Plus, specialized parsers require users to upload each file and make some external requests to these services, which incurs added costs and latency. PyPDF, on the other hand, is free and fast.
Financial Reports: Maybe nested tables work better?
The next type of document we chose to run through the parser is in Excel, and includes untrivial structures – merged cells, hierarchical columns, and so on, which most often come up in financial reports. In this case, we use Openpyxl as our parser. A user, for instance, might be interested to perform a certain analysis on such documents, either manually, or delegating it to an LLM.
Previous research indicates that using neural LLMs together with interpreters, like SQL-engines, drastically improves the success by which LLMs perform arithmetic and reasoning tasks. With this in mind, in both manual and LLM scenarios, it would make sense for the user to extract a table and convert it to such a format which could be put in a certain database.
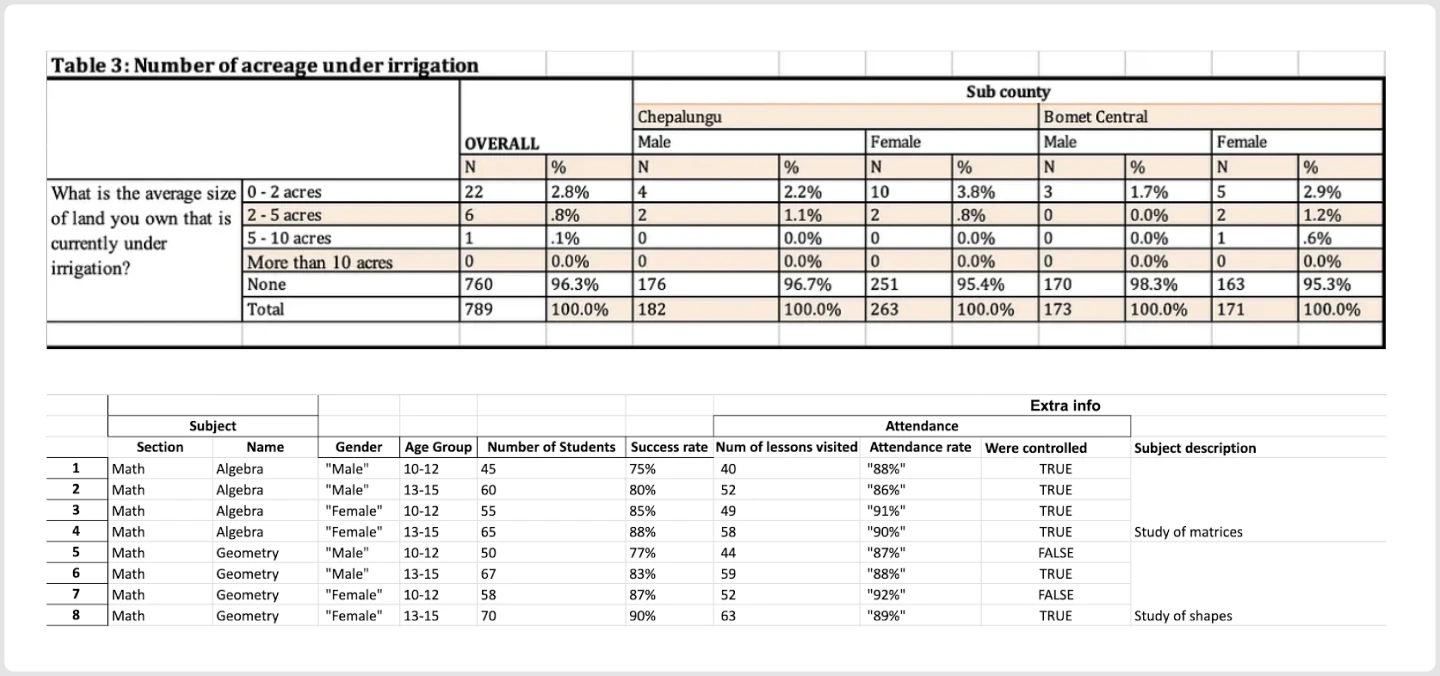
Let’s take a look at two nested Excel tables and the corresponding flat .CSV files (loaded as pandas. DataFrame) received by an automatic conversion of the schema.
Raw tables:
Parsed flat tables:
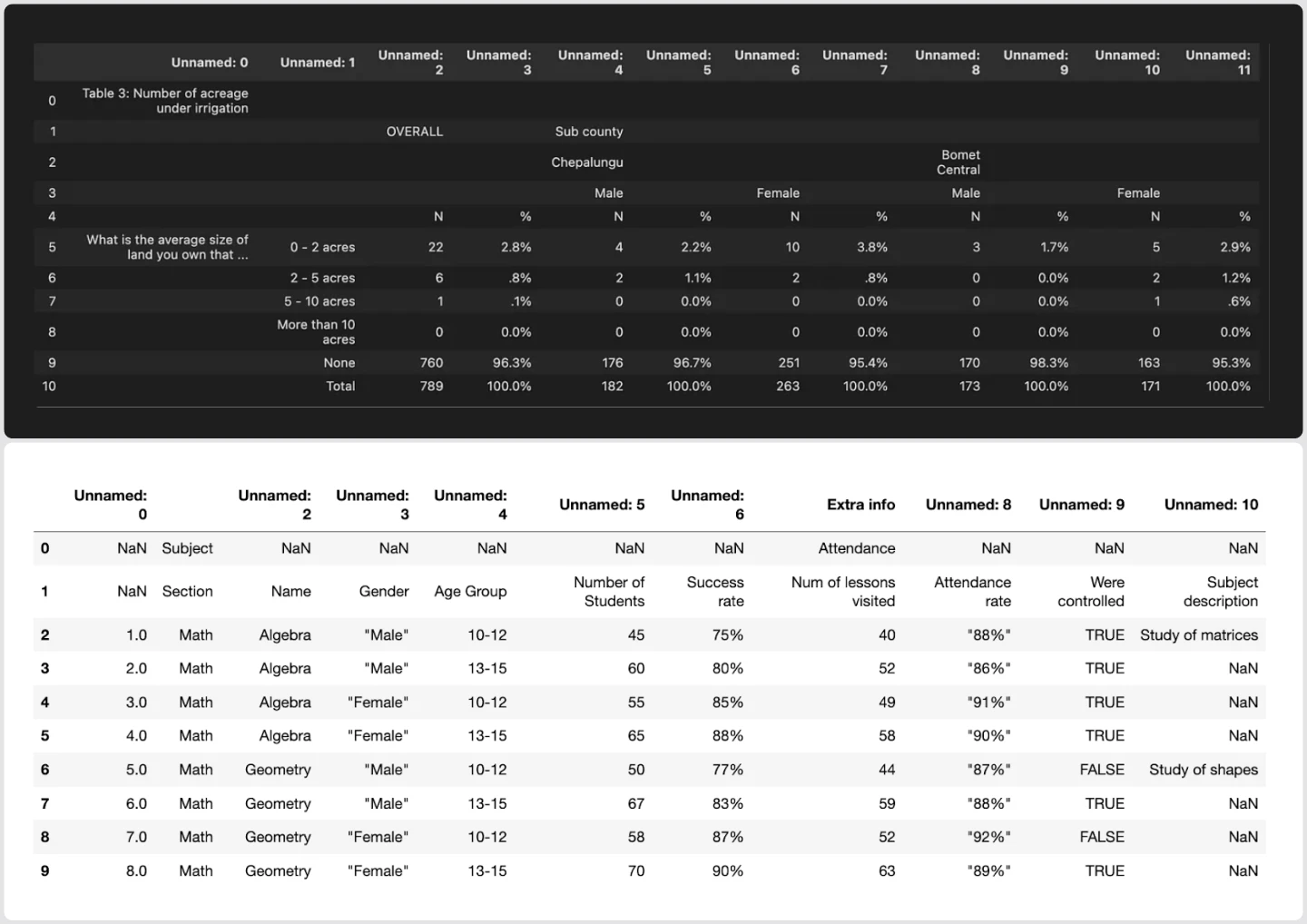
Once again, these parsed tables are nearly unusable: when we collapsed merged cells and nested columns, a ton of information got lost. If a user doesn’t have knowledge of the original table schema, or is hoping to avoid inspecting each document manually, parsers don’t provide a particularly helpful solution to processing documents with complex layouts and even introduce potential inaccuracies.
Where do we go from here?
The integration of LLMs into the document processing landscape has highlighted a significant hurdle: the intricate task of translating complex, structured documents into a comprehensible text format. Tools like Azure Form Recognizer and PyPDF, despite their advanced capabilities, struggle to grapple with diverse document layouts and distort informational flow. Their errors become especially consequential when dealing with multi-column documents, intricate tables, and scientific formulas. A misinterpretation or omission of even a single data point can lead to repercussions in industries where precision is important.
The challenges presented by these parsers might offer a unique opportunity for LLMs themselves. As we've observed, the current parsing tools' heuristic-based methods are brittle and often misrepresent critical information. Could it be possible to leverage the intricate understanding of LLMs to rectify the very errors these parsing tools introduce? The potential of LLMs might go beyond mere data comprehension; they could be the key to recovering lost or distorted information, and in turn, transform global industries. In our subsequent posts, we explore this very possibility: harnessing LLMs to mend the gaps in our current document processing methods.