Medical search engines and machine learning
Using search engines to look for information on medical issues takes up a significant percentage of all searches. Google first hit one trillion searches in 2011 and has never stopped climbing. In 2019, 7% of those were searches for something connected to medicine. That was before the COVID pandemic. So, medical search is a phenomenon.
On top of searches made on general purpose search engines such as Google, searches also take place on specialized search engines. This holds true in particular for the sciences and in medicine. Scientific journal search engines help researchers keep abreast of developments in their field. Without journal article search engines, surveying the field of research is extremely difficult these days.
The explosion in the popularity of electronic journals makes even a basic science search engine list a requirement. However, utilizing machine learning can lead to more efficient and adaptive searches. Search engines for medical research are a particularly rich area for utilizing machine learning. Moreover, bespoke search engines for medical research. How so? Let's take a look.
Medical Search Engine
A medical journals search engine helps you find published material about medical and life science issues. Such search engines have the advantage of collecting information from a variety of sources simultaneously instead of going to each journal's site individually. Most medical search engines would include several medical databases, such as EMBASE from the academic publisher Elsevier and MEDLINE, which is run by the U.S. government's National Library of Medicine. A medical journal search engine is a centralised online platform that allows you to find literature on any medical topic within seconds. Bioinformatics researchers have found using more than one platform for a targeted search produces broader search results compared to using only one search engine.
Searching medical literature has the same issues that general search engines deal with as well as some decisions that developers need to make that are particular to the field. Indexing and the weight given to social media in determining rankings are two common things search engine developers need to worry about. Building a vertical search engine, such as one that lets users search medical journals, brings developers to the same problem.
However, a developer working on the creation of an engine working within the biomedical domain has to deal with a set of issues that pertain to the field being searched. Part of the problem is in pinpointing who is the end user of the search engine. This affects everything from the user interface to ranking. Even if the search engine is geared toward medical professionals, the end user is a determining factor. Nursing search engines will have a different focus from those focused on cancer research. Answering the question of 'who' will be a focal point for a search engine architect, but the engineer building on the architect's vision will also make crucial decisions that affect the speed and accuracy of a search.
All this leads the search engine development team into some hard choices regarding algorithms and what kind of machine learning to use.
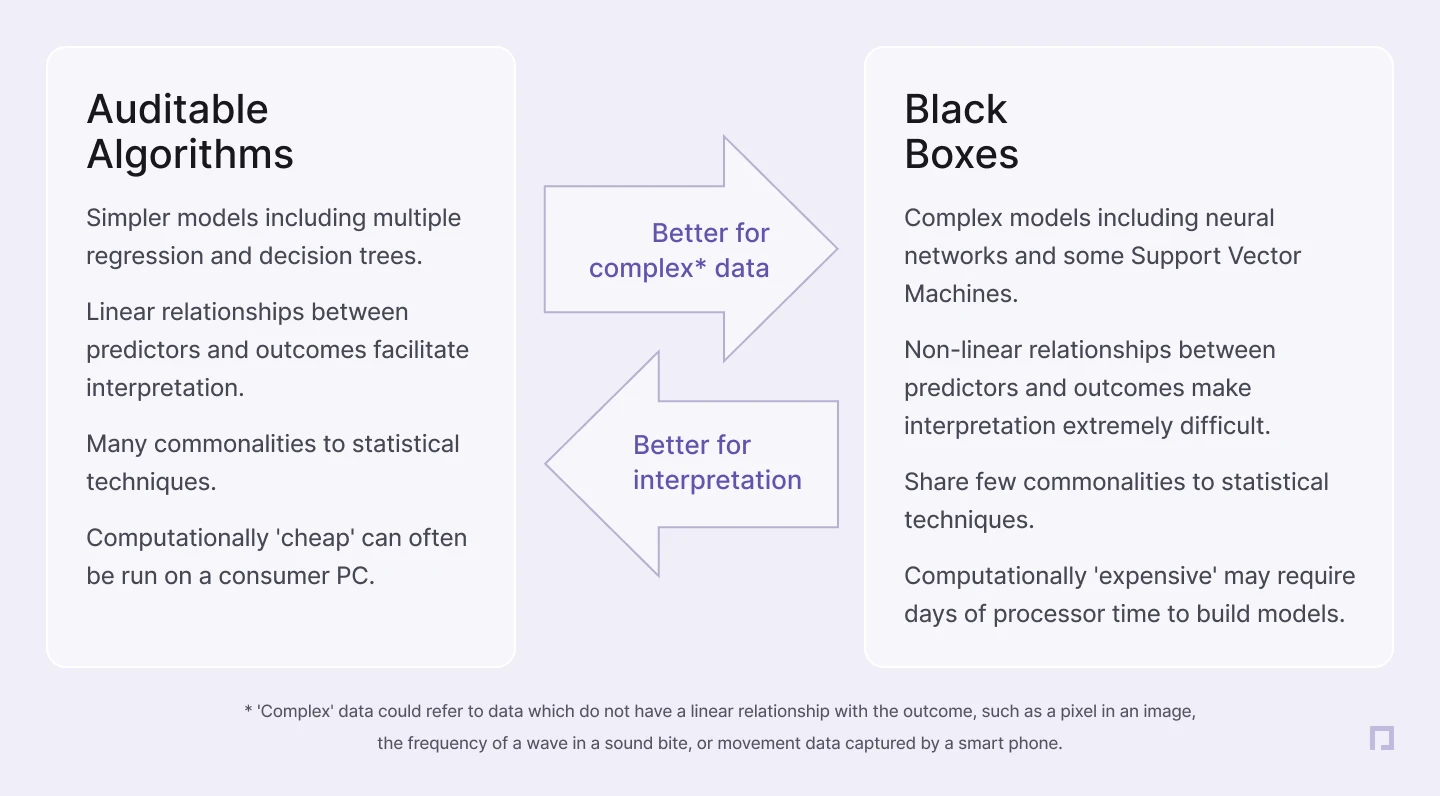
The image above illustrates just one of the basic decisions the team needs to make. For that to happen, the team needs to clearly understand what this particular institution requires in terms of search. A search platform focused on journal articles, one regarding regulatory issues, and a third geared toward handling images would be optimized in three different ways.
"While medical search engines for the general public touch on a very popular topic and many hospital systems have search capability regarding ailments and conditions, search engines for the medical field's professionals are at a whole different level. The complexity of systems that need to handle text, especially professional jargon, as well as images, and deliver the accurate results medical professionals need, really requires machine learning these days. Often, those platforms need to be created, and finding an IT partner with the experience it takes to properly implement such a project can be difficult."
— Vlad Medvedovsky, CEO at Proxet (ex - Rails Reactor) - a custom software development company.
Medical Terminology Indexation
Indexing is a problem for any type of search. However, the medical field is known for its use of jargon. While the use of shorthand is common to most disciplines, the medical field may confuse the uninitiated. Britain's Royal College of General Practitioners gave an example in a 2014 article in the British Journal of Medicine, in which doctors using the word 'chronic' to mean 'persistent' often gave the impression to patients that the case was more severe.
Search systems suffer from the same type of problem. User inputting jargon into search terms, or worse, putting jargon into metadata, sow chaos in search engines. Machine learning can work around this problem, with sufficient training. However, the institution's team needs to lead in this regard. IT partners can help when it comes to filling private data lakes, but searching through journal articles that are misindexed because of misapplied terminology or with systems that cannot adapt to such use will only limit the accuracy of the engine.
Article Search Engines
MEDLINE, one of the two most popular medical journal article search engines, is also one of the most comprehensive. However, in a 2017 article in Springer's Systematic Reviews Journal, the authors found that 60% of systematic reviews may "not retrieve 95% of all available relevant references as many fail to search important databases". In 'Optimal database combinations for literature searches in systematic reviews: a prospective exploratory study',
Not being able to find relevant articles by reviewers is an indication that the problems around journal article search are at a critical stage.
The authors solved the overwhelming majority of such problems by searching via multiple engines. They wrote that "The combination of Embase, MEDLINE, Web of Science Core Collection, and Google Scholar performed best, achieving an overall recall of 98.3 and 100% recall in 72% of systematic reviews."
The combination of mis-indexing and findability create problems that platforms utilizing machine learning can resolve. However, there are other issues that can complicate the issue further. The biggest of these issues: images.
Medical Image Analysis
Verified Market Research put the overall image research market size at $30.28 Billion as of 2020. The company expects the market to reach $115.56 Billion by 2028, thus implying a CAGR of 18.25% from 2021 to 2028. This includes everything from facial recognition to geolocation to barcode reading.
Within the life sciences field, and within medicine in particular, image analysis the market growth is slower. According to Vantage Research in January 2022, the global medical image analysis market will grow at a CAGR of 7.9% through 2028. Vantage Research sees the market size hitting $5.79 billion by 2028 as well. That's just analysis. Grand View Research put the overall global medical imaging market at $28.02 billion in 2021 with a CAGR 4.9% from 2022 to 2030.
The issue for machine learning might not be the quantity of the data, but rather the quality. This might come as a surprise, given that attendees of the 2016 Conference on Machine Intelligence in Medical Imaging (C-MIMI) in Alexandria, Virginia, in the U.S., agreed that one of the main problems for machine learning for medical imagery was that practitioners were data starved. There simply were not enough data sets that were properly indexed and anonymized for machines to work with. In a white paper from the conference, the state of the art was encapsulated with the need to describe the essential characteristics of the imagery data set.
"The ideal medical image dataset for an ML application has adequate data volume, annotation, truth, and reusability. At base, each medical imaging data object contains data elements, metadata, and an identifier. This combination represents an “imaging examination.” A collection of data objects or dataset must have enough imaging examinations to answer the question being asked. To maximize algorithm development, both the dataset itself and each imaging examination must be described and labeled accurately. Ground truth, the classification label(s) of each imaging examination, should be as accurate and reproducible as possible."
— Marc Kohli, Associate Chair of Clinical Informatics, UCSF.
Five years and a global pandemic later, the issue might be solved in terms of quantity, but other points raised by Kohlii, Summers, and Geis still hold as 'in process'. Metadata and identifier issues still exist. However, a bootstrapping problem, namely in classification, is still endemic across specialties. This raises problems when it comes to creating the metadata in the first place. In that sense, the ground truth problem they point to has not gone away.
This raises problems for the search engine development team. Experience in dealing with the medical field becomes vital, and not because a programmer needs to be able to look at a CAT scan and understand subtle differences. The variety and volume of data being dealt with raises problems beyond a 'simple' issue of data lake versus data swamp. Handling data reclassification of large data sets within a data lake, or changing terminology, will be the mark of a supple data storage - as well as the mark of a supple medical search engine working with those lakes along with external databases.
Working with the correlation between image and text searches will also be a problem for ML-based search engines for medical research. It is in research, where terminology might remain unclear, that machine learning holds promise after the bootstrapping issues above are solved. Again, this is not a problem found only in the medical field, but the need for a work-around for this very human issue is particularly acute in medicine.
Best Medical Database
There is no overall best database. Some who work in the industry can successfully utilize existing online engines for a simple medical article search. Springer's Medline search engine would be a good example of this. It is very popular within the discipline, and, as Springer claims, covers the largest amount of medical journals.
Others, in an environment where a data lake holds all of the items for the search, may need an institutional system utilizing the ecosystem of the respective data lake. However, the argument can be made that a bespoke medical search system utilizing machine learning to continually sharpen its accuracy.
The only way to determine which route to take is to take the time to accurately determine your organization's medical search requirements. For starters, take the following points into consideration:
- What are the users' primary roles, and what range of roles can be expected? A research-based medical search engine and a practitioner-focused one will be very different. Do you need to cover them both?
- What sources will the search engine be dealing with: internal data lakes, external article repositories?
- Will the searches concentrate mostly on text or on images? If both, which takes priority? Will the ML need to be sufficiently supple to recognize underlying similarities when outwardly, there are mismatches between the two?
- Does your organization have the capacity to build and maintain a medical search engine that utilizes machine learning? If not, is it ready to partner with a technology company that has experience in the field?
- A "good" medical search engine and machine learning platform is a moving target. Does the institution expect a 'set-and-forget' system? If so, some very basic groundwork regarding the platform's evolution over time might be required.
Conclusion
The digital transformation of the medical field has brought about sea changes to how health care is researched, delivered, and reported. However, the challenges of the present system are likely to stay in focus as the next generation of researchers and practitioners comes aboard. This generation is already envisioning what that future will be like. Here's a vision for health care governance in 2030. With this level of digitalization expected, those who want to work with the best will need to invest today into the systems they will use.
