Building end-to-end data-driven business solutions with Palantir Foundry and AIP
Written by Kris Gumplowicz and Adriana Calomfirescu
A lot of companies already have solid data foundations – data warehouses or lakes, BI, even ML – but they still struggle to turn insights into real action. The problem usually isn’t a lack of raw data. It’s that analytics remains siloed, separate from day-to-day workflows, decision making, and the systems where people actually get work done.
Palantir Foundry bridges this gap by enabling teams to build governed, end-to-end applications directly on top of enterprise data. Rather than stitching together fragmented tools, the platform converges data integration, business modeling, and user interfaces into a single environment. This architectural core serves as the essential foundation for Palantir AIP, which layers modern AI and automation directly into these governed workflows, ensuring that insights move beyond dashboards and into the heart of operations.
As a Palantir partner, Proxet helps organizations design, deliver, and optimize these platforms with a focus on moving fast, staying modular, and driving real business outcomes.
Why Proxet chooses Palantir Foundry to build solutions for clients
Palantir Foundry is an enterprise platform for building operational data products. While traditional platforms stop at "insights" — dashboards, reports, and offline analysis — Foundry extends the data lifecycle into action. It enables interactive applications where users and automated processes explore data in context, execute decisions, and write back to operational systems — all while maintaining unified governance, lineage, and permissions. With AIP, Palantir connects LLMs directly to this governed foundation, ensuring AI drives real-world automation rather than remaining trapped in isolated prototypes.
Development process overview
1. Model the business
The Ontology is where an enterprise is modeled as it actually operates: – defined by business objects, relationships, and properties. This structure ensures that teams work with recognizable business entities rather than raw rows of data.
This is more than a semantic layer. Ontology properties can be rich and complex — incorporating time series and media-like artifacts — with objects connected through explicit relationships that reflect real-world workflows. Ontology Actions provide controlled methods to create or update objects, ensuring "write-back" is an inherent part of the design rather than an afterthought. Consequently, applications operate on these business objects consistently across all use cases.
For the business, this establishes a shared language across teams and systems. It reduces delivery friction because each new use case reuses the existing object model and actions instead of rebuilding logic from scratch. Finally, access controls and permissions are defined at the Ontology Action level, ensuring consistent security and data privacy across the entire ecosystem.
2. Hydrate the Ontology with data
Once business objects are defined, they are hydrated from enterprise source systems — both structured and unstructured — ensuring downstream work remains independent of raw pipelines or brittle transformations.
This architecture marks a fundamental departure from "pipeline-first" approaches. In this model, pipelines exist solely to maintain an accurate and trustworthy Ontology, while the end-user experience is built on business objects and their relationships. This prevents the common issue of multiple teams interpreting the same datasets differently. Furthermore, the platform provides native capabilities to merge automated pipeline data with direct user edits, employing built-in conflict resolution strategies to maintain data integrity.
3. Event-driven orchestration
Real operational value comes when the platform responds to changing reality: an object is created, a property changes, a time series threshold is exceeded or a relationship is added (e.g., supplier ↔ incident). Foundry enables event-driven orchestration based on those object-level changes, so workflows can trigger reliably and consistently across use cases – rather than being implemented as one-off scripts. This is where “data platform” becomes “operating platform.”
4. Activate AI in this environment
AIP Logic provides a no-code environment for building complex processes that run directly on Ontology objects. It enables the implementation of sophisticated, LLM-based workflows that query the Ontology for context, extract information from unstructured documents, link discovered facts to specific entities, and trigger governed actions to execute approved steps.
For example, an AIP Logic workflow can scan a collection of PDF documents to identify mentions of a specific company and a business event—such as an IPO, acquisition, or merger. The system then automatically links the extracted evidence to the relevant Company object, updates its properties, and surfaces the results on a centralized dashboard. Simultaneously, it can generate investment briefs or risk memos and route them to the appropriate recipients.
The core value is not found in simple "AI summarization." Instead, it lies in AI embedded directly into business processes, grounded in a unified data model, and capable of producing traceable, high-stakes actions.
5. Deliver the experience
Finally, workflows are delivered to end-users through interactive applications and dashboards built directly on the Ontology. Two primary environments facilitate this in enterprise scenarios:
- Workshop: Used to build interactive applications on top of Ontology objects. These interfaces allow users to explore entities, investigate issues, and execute actions within a specific business context.
- Quiver: Used to create live dashboards and perform complex time-series transformations. This enables real-time operational monitoring and analytics on streaming or continuously updated data.
This layer makes the end-to-end model tangible: users do not merely view static results; they interact with the same governed business objects and processes that power the entire platform.
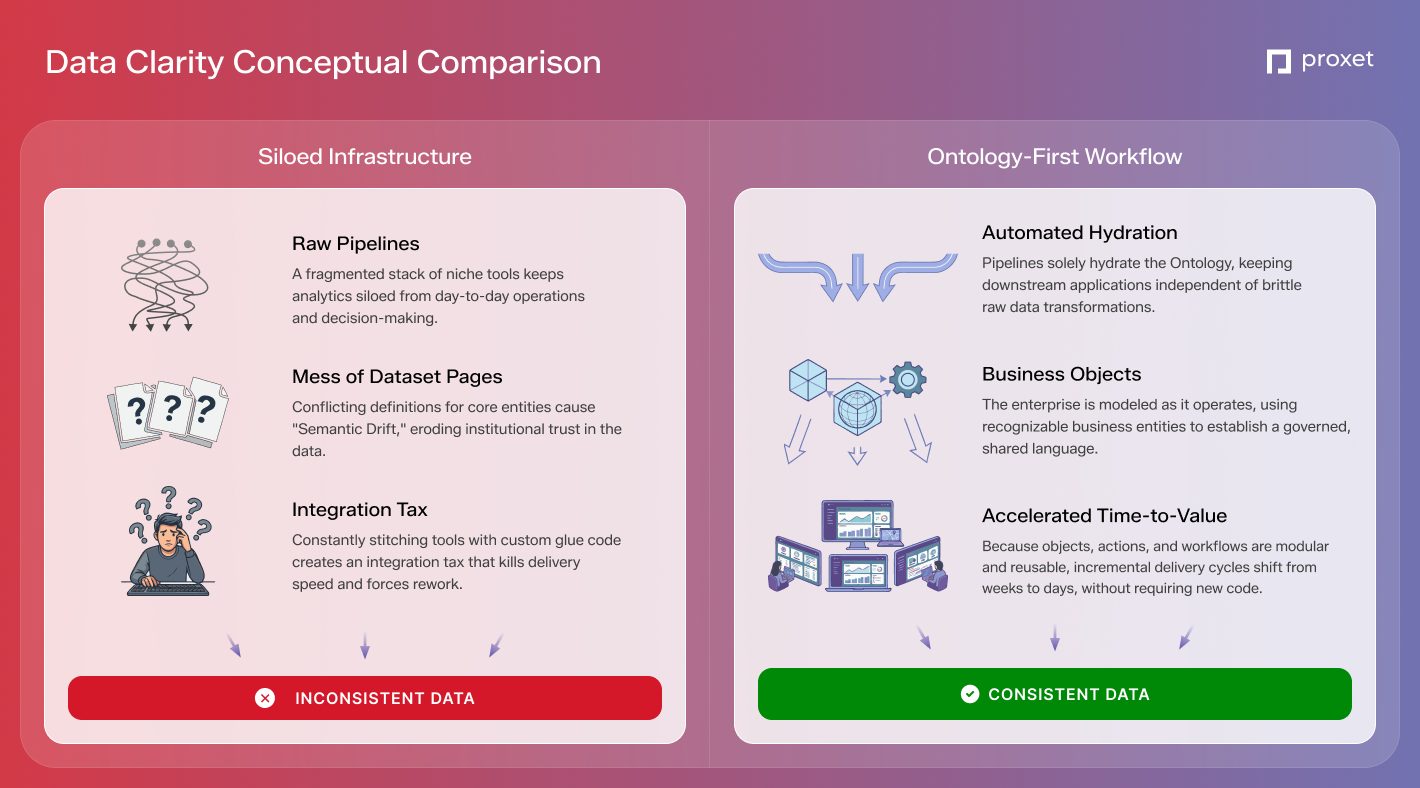
How this differs from most data stacks
Most organizations build data capabilities by stitching together a fragmented stack of niche products: data lakes / data warehouses for storage, ETL / ELT tools for pipelines, BI suites for reporting, and separate environments for AI experimentation or app development.
While this modular approach is common, it inevitably triggers three systemic challenges:
- Semantic Drift: Different systems adopt conflicting definitions for core entities — such as "customer" or "asset status" — eroding institutional trust in the data.
- The Integration Tax: Every new workflow necessitates a bespoke integration project, diverting resources from functional progress to infrastructure maintenance.
- Stagnant Time-to-Value: Delivery speed is throttled by team handoffs and the rework required to align mismatched assumptions across tools.
Palantir’s core innovation is the consolidation of these functions around a governed Ontology and reusable actions. This creates a functional business operating layer rather than another disconnected analytics tier.
A significant advantage of this architecture is the accessibility of no-code and low-code tools. This enables faster iteration and ensures teams follow consistent patterns. Because objects, actions, and workflows are modular, they can be reused across the enterprise instead of requiring new "glue code" for every use case. In practice, once this foundation is established, incremental delivery cycles often shift from weeks to days.
Furthermore, the platform remains an open ecosystem. Under the hood, data transformation is powered by Apache Spark, and custom Python or TypeScript functions can be integrated across any layer where specialized logic adds value — all without sacrificing the benefits of a unified, governed platform.
Outcomes
When an end-to-end Palantir platform is implemented effectively, it establishes a singular, business-friendly view of the entire organization through Ontology. In this environment, real-world events are not merely logged as static entries; they trigger operational workflows automatically, enabling the business to react instantaneously rather than waiting for manual intervention or delayed updates.
Teams no longer navigate fragmented, disconnected tools. Instead, Workshop translates shared context into actionable applications, while Quiver ensures that operational monitoring remains tied to live, evolving objects. Layered on top, AIP Logic integrates AI into the ecosystem in a way that is grounded in governed enterprise data and focused on production outcomes rather than isolated experiments.
The primary payoff is a measurable shift in organizational performance: accelerated response cycles, the elimination of manual handoffs, and clear accountability from the initial insight through to the final action.
This is the core focus of Proxet. We build solutions designed to survive the realities of production — messy data, shifting requirements, and real-world business constraints. For clients, this translates into outcomes that can be deployed in days and scaled immediately. For engineers, it means developing systems that fundamentally change how an organization operates, moving beyond simple reporting to true operational transformation.