Is error-free parsing possible? Part II
Written by Hanna Pylieva
In part one of our ongoing theme exploring Large Language Model (LLM) for document parsing - Is error free parsing possible -, we established that leaders across all business sectors can gain efficiencies and cut costs by harnessing LLMs to help interpret documents with complex layouts. We found that while a popular, non-proprietary parser like PyPDF improved document understanding, it struggled to translate complex, structured documents into comprehensible text formats. Moreover, expensive proprietary parsers like AzureForm Recognizer don’t necessarily improve accuracy. Testing multiple use cases, we found these parsers often made errors when interpreting various complex document structures (meaning documents with formulas, grids, or tables). Parsers were often slow, and in some cases, even introduced new mistakes rather than resolved them.
It’s time to problem-solve.
Might it be possible to harness LLMs themselves to resolve those errors introduced by parsing tools? We think so! While LLMs continue to struggle with complex layouts on their own, we can use them to determine the complexity of each document's structure by harnessing them to interpret whether or not a document includes formulas, grids, tables, and so on. After establishing each document's unique heuristics, LLMs can actually help select the most suitable parser. Here, we establish a tailored approach to parsing: one that relies on automation while still improving accuracy and in turn, increasing efficiency.
In our initial experiments, we compared four parsers:
- PyMuPDF - an open-source parser, which is frequently used in different modern solutions for document understanding out of the box
- PDFMiner - another open-source parser, which uses slightly different heuristics for the extraction of text from PDF documents
- Azure Form Recognizer - a proprietary parser from Azure, which is good at parsing tables, but takes more time and money to parse documents than PyMuPDF
- MaxPix - a proprietary parser with a great understanding of formulas.
We found that while all parsers failed to improve accuracy — and in many cases, even induced new errors—some were better at parsing certain documents than others. The overall schema of the parser selection process can be summarized as follows:
In our experiment, we sought to analyze text containing tables and scientific formulas. Our goal was to see if the LLM could determine if the document a) contained tables or was an academic paper and b) subsequently, have the LLM choose the proper parser for this purpose. The overall schema of the process can be found below:
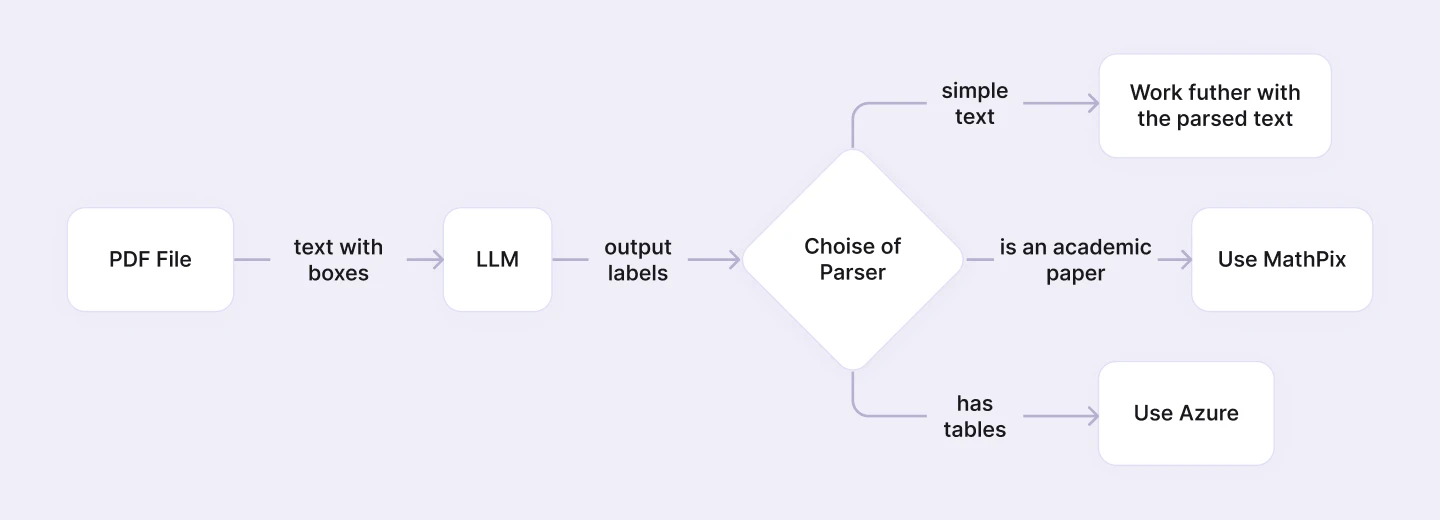
The idea is to use an open-source parser for basic document parsing; extract text with corresponding bounding boxes within the document and then pass this information to LLM with a request to provide a short inference on the document’s structure. We can ask the LLM for example, to conclude whether there are tables in the document, how many of them are there, and if this document is an academic paper or not. Based on the LLM’s output, we can then decide whether to proceed working with the initial parsed information or use a more complex parser to improve document layout understanding.
In our evaluation of Azure form Recognizer on a particular document, we observed the following results in terms of detection:

We can see that tables were properly identified, as well as text is detected much more accurately.
In our evaluation of MaxPix on a particular document, we observed the following results in terms of detection:
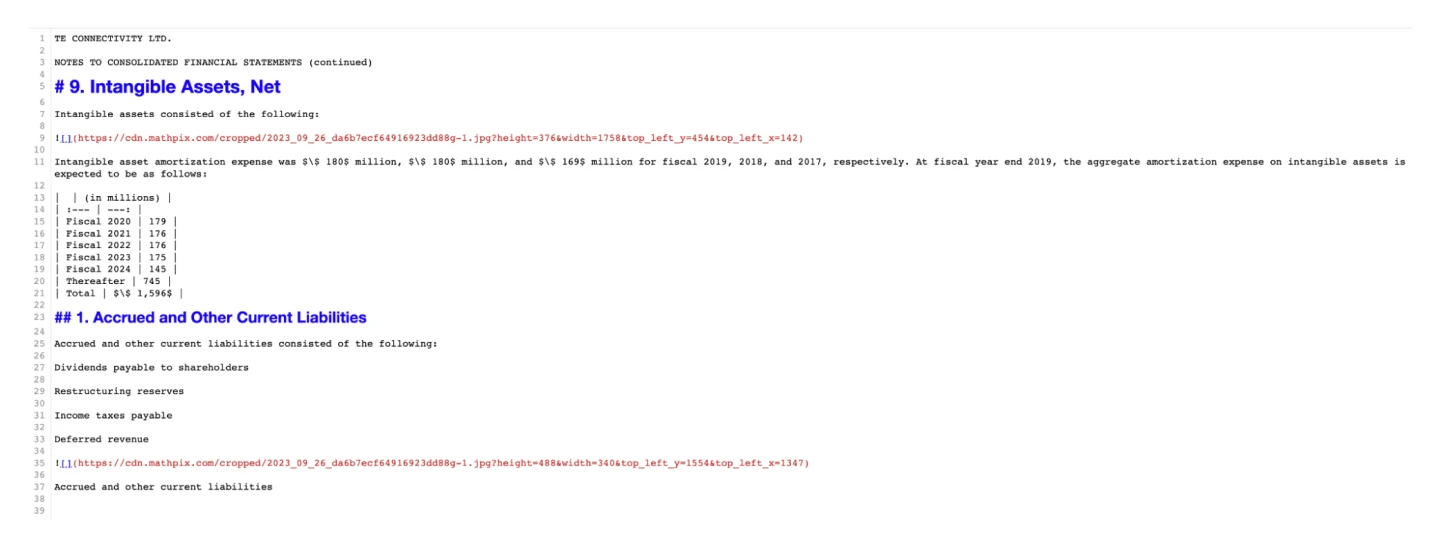
MaxPix failed to detect two tables. Consequently, it only extracted images of these undetected tables and suggested embedding them directly into the markdown.
For table detection, only one parser among the three we’re experimenting with, provides better results than the others. We showed in our prior article, Is error free parsing possible, embedded formulas are detected best by MathPix. Neither Azure, nor PyMuPDF are capable of parsing formulas correctly. These results were the motivation for our investigation.
LLM for structural analysis of the document
Our objective was to extract structural information from PDF documents, focusing on text blocks and their corresponding bounding boxes. The extracted data was then fed into the LLM model (ChatGPT 4, using 32k tokens) to ascertain:
- the presence of tables within the document,
- the quantity of tables embedded, and
- the classification of the document as an academic paper or otherwise.
The findings derived from the LLM's structural analysis play a crucial role in determining the appropriate parser to employ. The complexity and intricacy of each document’s structure informs whether a proprietary parser for detailed table extraction is warranted, a specialized parser for academic papers is necessitated, or if an open-source parser suffices for the task at hand.
For this experiment we handpicked documents from publicly available datasets featuring complex structures. This collection encompasses financial reports, scholarly articles, and scanned documents – each presenting a unique set of challenges for text and data extraction.
Our dedicated internal team annotated the financial and scanned documents (71 documents in total). This involved extracting text in the proper order from documents and identifying tables, ensuring each piece of content is accurately represented. Each table, marked as <TABLE_N>, was then cataloged separately, maintaining the integrity of the document’s structure. This annotation process was done in order to have ground truth data, enabling us to measure the quality of how the parser extracts text from documents and identifies tables.
Additionally, we have established ground truth labels to identify academic articles within the dataset. As manual annotation of scientific formulas is a complex process, the academic documents we’ve performed table detection and extraction using Azure Form Recognizer, include those documents in our dataset for validation.
The Experiment
We’ve run our documents through a PyMuPDF parser and then fed extracted text with corresponding bounding boxes to an LLM with the following system message:
We have measured the following quality metrics of our solution (open-source parser + LLM):
- F1-score of whether the LLM identified correctly that this document is an academic paper
- F1-score of whether the LLM identified whether there are tables in the document
- Mean absolute value of number of detected tables in the document.
The Results
Our results for 60 annotated the financial and scanned documents:
'academic_paper_f1': 1.0,
'n_tables_MAE': 0.38,
'tables_exist_f1': 0.98
A scanned document by PyMuPDF returned “<image: DeviceRGB, width: 777, height: 1000, bpc: 8>”. It was incapable of processing images; these documents required a tool with OCR (Optical Character Recognition).
Our results for 19 academic documents:
'academic_paper_f1': 1.0,
'n_tables_MAE': 0.84,
'tables_exist_f1': 0.84
From these results, we can conclude that PyMuPDF open-source parser is capable of providing enough information (extracted text and coordinates of bounding boxes of text blocks) to the LLM to identify 100% correctly whether this document is an academic paper, and a good F1 score to say whether the document contains tables or not (for these financial and academic documents). Our solution also allowed us to estimate how many tables were in the document with only a single error.
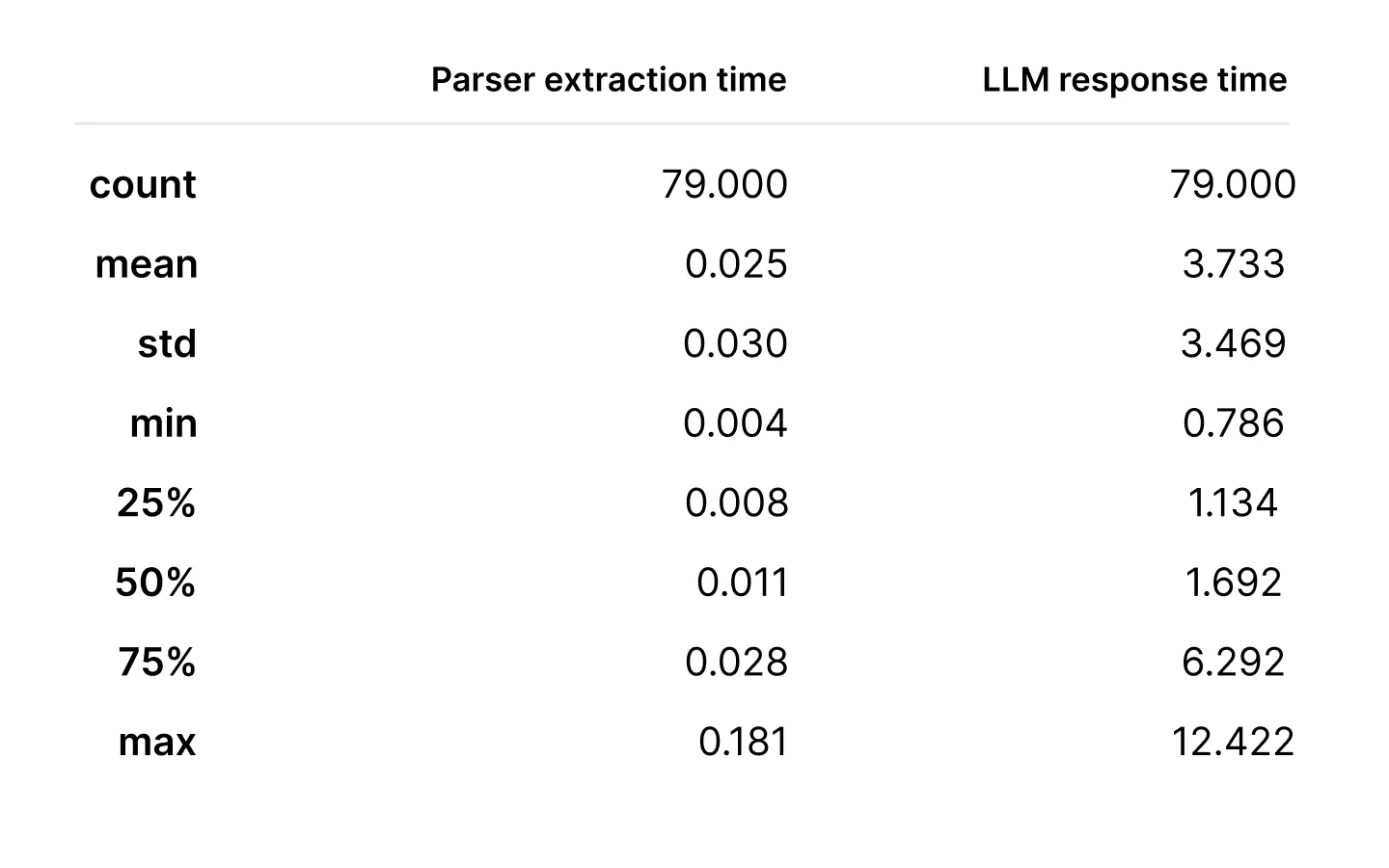
As part of our experiment, we also measured the latency of text extraction and LLM response generation for the provided text. The measurements are following (only for financial and scanned documents):
The costs of requests to the LLM were the following (in USD):
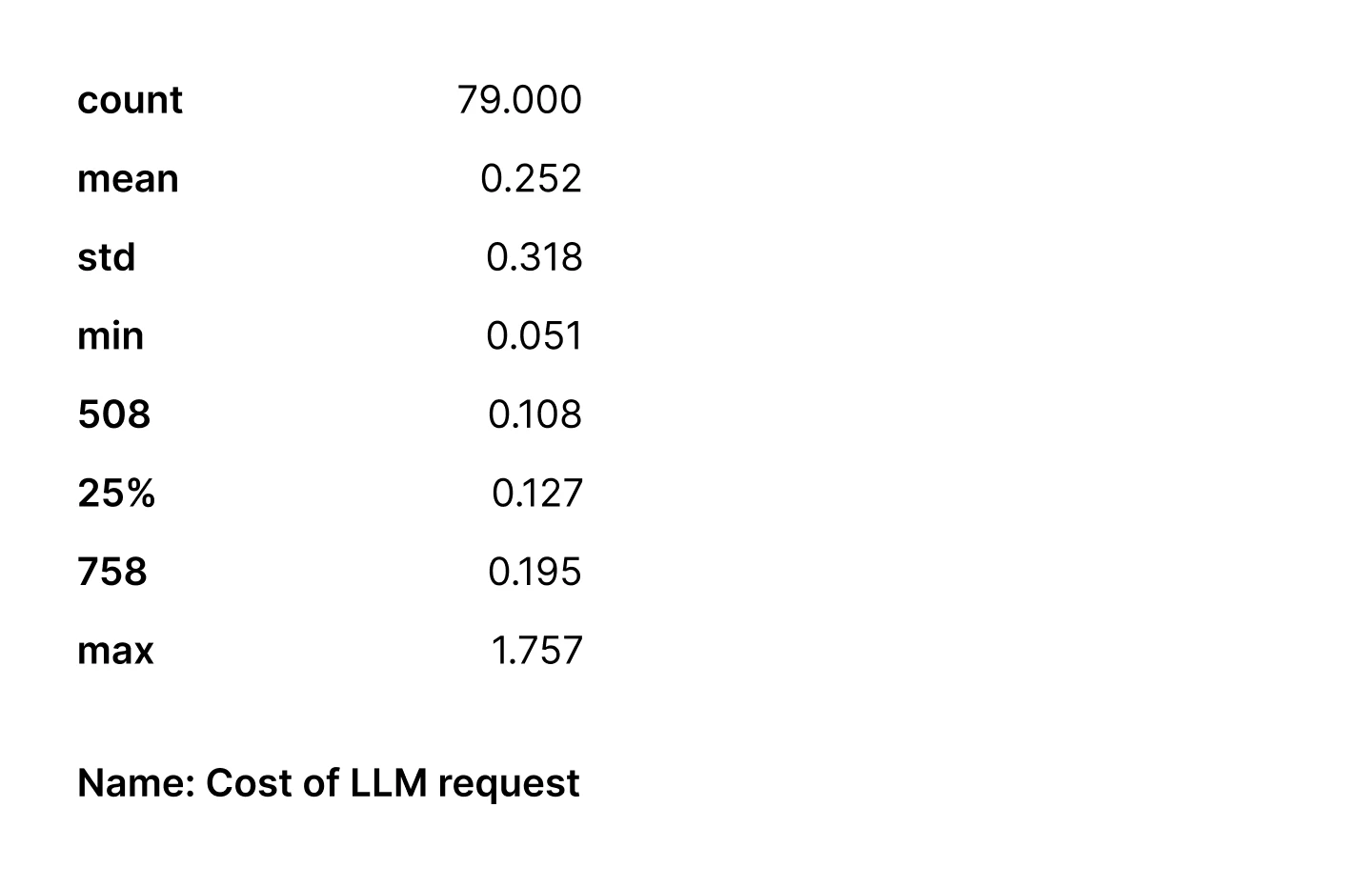
A median of 12.7 cents and 1.7 seconds per request to the LLM to identify document structure and redirect further document processing to a proper parser for this document looks reasonable for our team — if we compare the costs of applying all the tools on each document and then merging the results. For related insights, we’ve previously explored latency, prompt size, and cost in growing LLM usage: llm-has-a-performance-problem-inherent-to-its-architecture-latency
Conclusion
Our investigation into leveraging a LLM for structural interpretation of documents has yielded encouraging outcomes. In an era dominated by an explosion of unstructured data and complex document layouts, the ability to swiftly and accurately discern the underlying structural intricacies is paramount. It underpins not just efficient data extraction, but also the subsequent analytics applications that drive informed decision-making.
Through our experimental approach, utilizing both open-source and proprietary parsers in tandem with the LLM, we were able to navigate the challenges posed by complex table layouts and scientific formulas embedded within documents. The preliminary results underscore the viability of this methodology, especially in enhancing the precision and cost-effectiveness of document parsing.
Key Findings:
1. Effectiveness of the LLM. The LLM exhibited remarkable accuracy in classifying documents as academic papers, and in identifying the presence and number of tables within the documents – utilizing data extracted by the open-source PyMuPDF parser.
2. Accuracy and Cost-Efficiency. The combination of the open-source parser and LLM demonstrated a balanced mix of accuracy and cost-efficiency. It provided a practical solution for distinguishing between different types of documents and determining the appropriate parsing tool to employ.
3. Performance Metrics. With F1-scores reflecting high accuracy and mean absolute error indicating reliable table count estimations, the open-source parser coupled with LLM stands as a promising solution for automated document structure identification and parsing.
4. Latency and Cost Considerations. The observed median latency and cost per LLM request underscore the model’s operational efficiency, marking it as a viable option for real-time applications, especially when juxtaposed with the potential costs of utilizing proprietary parsers indiscriminately.
Future Directions:
As we move forward, we anticipate that LLM’s training and inference mechanisms will need to be continuously refined to further enhance performance. The prospect of integrating optical character recognition (OCR) tools to augment the processing of scanned documents is also on the horizon. This holistic approach melds advanced parsing techniques with the analytical prowess of the LLM and promises to significantly elevate the efficiency and accuracy of extracting structured data from an eclectic array of complex documents.
In the meantime, our positive outcomes affirm the instrumental role that LLMs can play in the intricate dance of document parsing and structural understanding. Our exploration stands as a testament to the potential synergies between machine learning models and parsing tools – opening avenues for enhanced data extraction, analysis, and utilization in the dynamic landscape of digital information.